Because you should use the right tool for the right task: you should not rely on regexps to validate IBAN numbers, but instead use the IBAN checksum algorithm to check the whole code is actually correct, making any regexp superfluous and redundant. i.e.: remove all spaces, rearrange the code, convert to integers, and compute remainder, here it's best explained.
Though, there am I trying to answer your question, for the fun of it:
what about:
^DE([0-9a-zA-Z]s?){20}$
which only difference is allowing a whitespace (or not) after each occurence of a alphanumeric character.
here is the visualization:
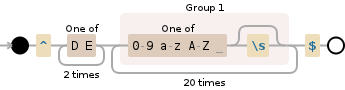
edit: for the OP's information, the only difference is that this regexp, from @ulugbex-umirov: (?:s*[0-9a-zA-Z]s*) does a lookahead check to see if there's a space between the iso country code and the checksum (which only made of numerical digits), which I do not support on purpose.
And actually to support a correct IBAN syntax, which is formed of groups of 4 characters, as the wikipedia page says:
^DEd{2}s?([0-9a-zA-Z]{4}s?){4}[0-9a-zA-Z]{2}$
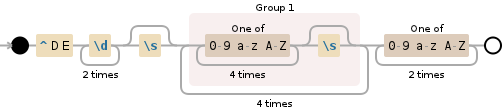
example
If your UI is in Javascript, you can use that library for doing IBAN validation:
<script src="iban.js"></script>
<script>
// the API is now accessible from the window.IBAN global object
IBAN.isValid('hello world'); // false
IBAN.isValid('BE68539007547034'); // true
</script>
so you know this is a valid IBAN, and can validate it before the data is ever even sent to the backend. Simpler, lighter and more elegant… Why do something else?
与恶龙缠斗过久,自身亦成为恶龙;凝视深渊过久,深渊将回以凝视…



