Here is the scenario I find myself in.
I have a reasonably big table that I need to query the latest records from. Here is the create for the essential columns for the query:
CREATE TABLE [dbo].[ChannelValue](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[UpdateRecord] [bit] NOT NULL,
[VehicleID] [int] NOT NULL,
[UnitID] [int] NOT NULL,
[RecordInsert] [datetime] NOT NULL,
[TimeStamp] [datetime] NOT NULL
) ON [PRIMARY]
GO
The ID column is a Primary Key and there is a non-Clustered index on VehicleID and TimeStamp
CREATE NONCLUSTERED INDEX [IX_ChannelValue_TimeStamp_VehicleID] ON [dbo].[ChannelValue]
(
[TimeStamp] ASC,
[VehicleID] ASC
)ON [PRIMARY]
GO
The table I'm working on to optimise my query is a little over 23 million rows and is only a 10th of the sizes the query needs to operate against.
I need to return the latest row for each VehicleID.
I've been looking through the responses to this question here on StackOverflow and I've done a fair bit of Googling and there seem to be 3 or 4 common ways of doing this on SQL Server 2005 and upwards.
So far the fastest method I've found is the following query:
SELECT cv.*
FROM ChannelValue cv
WHERE cv.TimeStamp = (
SELECT
MAX(TimeStamp)
FROM ChannelValue
WHERE ChannelValue.VehicleID = cv.VehicleID
)
With the current amount of data in the table it takes about 6s to execute which is within reasonable limits but with the amount of data the table will contain in the live environment the query begins to perform too slow.
Looking at the execution plan my concern is around what SQL Server is doing to return the rows.
I cannot post the execution plan image because my Reputation isn't high enough but the index scan is parsing every single row within the table which is slowing the query down so much.
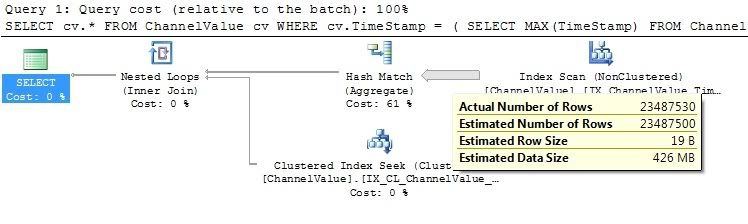
I've tried rewriting the query with several different methods including using the SQL 2005 Partition method like this:
WITH cte
AS (
SELECT *,
ROW_NUMBER() OVER(PARTITION BY VehicleID ORDER BY TimeStamp DESC) AS seq
FROM ChannelValue
)
SELECT
VehicleID,
TimeStamp,
Col1
FROM cte
WHERE seq = 1
But the performance of that query is even worse by quite a large magnitude.
I've tried re-structuring the query like this but the result speed and query execution plan is nearly identical:
SELECT cv.*
FROM (
SELECT VehicleID
,MAX(TimeStamp) AS [TimeStamp]
FROM ChannelValue
GROUP BY VehicleID
) AS [q]
INNER JOIN ChannelValue cv
ON cv.VehicleID = q.VehicleID
AND cv.TimeStamp = q.TimeStamp
I have some flexibility available to me around the table structure (although to a limited degree) so I can add indexes, indexed views and so forth or even additional tables to the database.
I would greatly appreciate any help at all here.
Edit Added the link to the execution plan image.
See Question&Answers more detail:
os 


