
-
 客服电话
客服电话
-
 APP下载
APP下载
迪恩网络APP
随时随地掌握行业动态

-
 官方微信
官方微信
扫描二维码
关注迪恩网络微信公众号
客服电话
APP下载
迪恩网络APP
随时随地掌握行业动态
官方微信
扫描二维码
关注迪恩网络微信公众号
开源软件名称:vw-crawler开源软件地址:https://gitee.com/backwxc/vw-crawler开源软件介绍:VW-Crawler
背景自己一直对爬虫比较感兴趣,大学的毕业论文也是一个爬虫项目(爬教务处信息,然后做了个Android版教务管理系统,还获得了优秀毕业设计的称号),自那以后遇到自己感兴趣的网站就会去抓一下。前段时间工作上需要一些JD信息,我就从网上找了个开源的爬虫框架WebMagic,使用简单,易配置,功能也很强大,当然了也有些网站的数据不适合使用。前前后后写了不下十几个,慢慢的就想是不是可以把这些爬虫代码再抽象出来,做出一个简易的爬虫框架呢?于是就尝试去看WebMagic的源码,后来又发现了一个源码比较容易解读的爬虫框架XXL-CRAWLER,简单的分析了源码之后,开发自己一套爬虫框架的欲望更加强烈,于是在2017年底的时候就开始了开发,中间断断续续得停了写,写了停。直到最近8月底的时候才算出了一个版本,然后顺势把它放到了Maven公服仓库上。一个人的力量很薄弱,要想完善这个爬虫的健壮性、可用性和易扩展性还需要大家的力量! 2019年8月20日09:30:59 更新 过去12月内的下载使用情况 特点
使用使用Maven在http://search.maven.org上使用最新的版本在pom中引入 <dependency> <groupId>com.github.vector4wang</groupId> <artifactId>vw-crawler</artifactId> <version>${last.version}</version></dependency>离线使用可以在项目主页的release下载最新版本jar,然后导入自己的项目中。 步骤
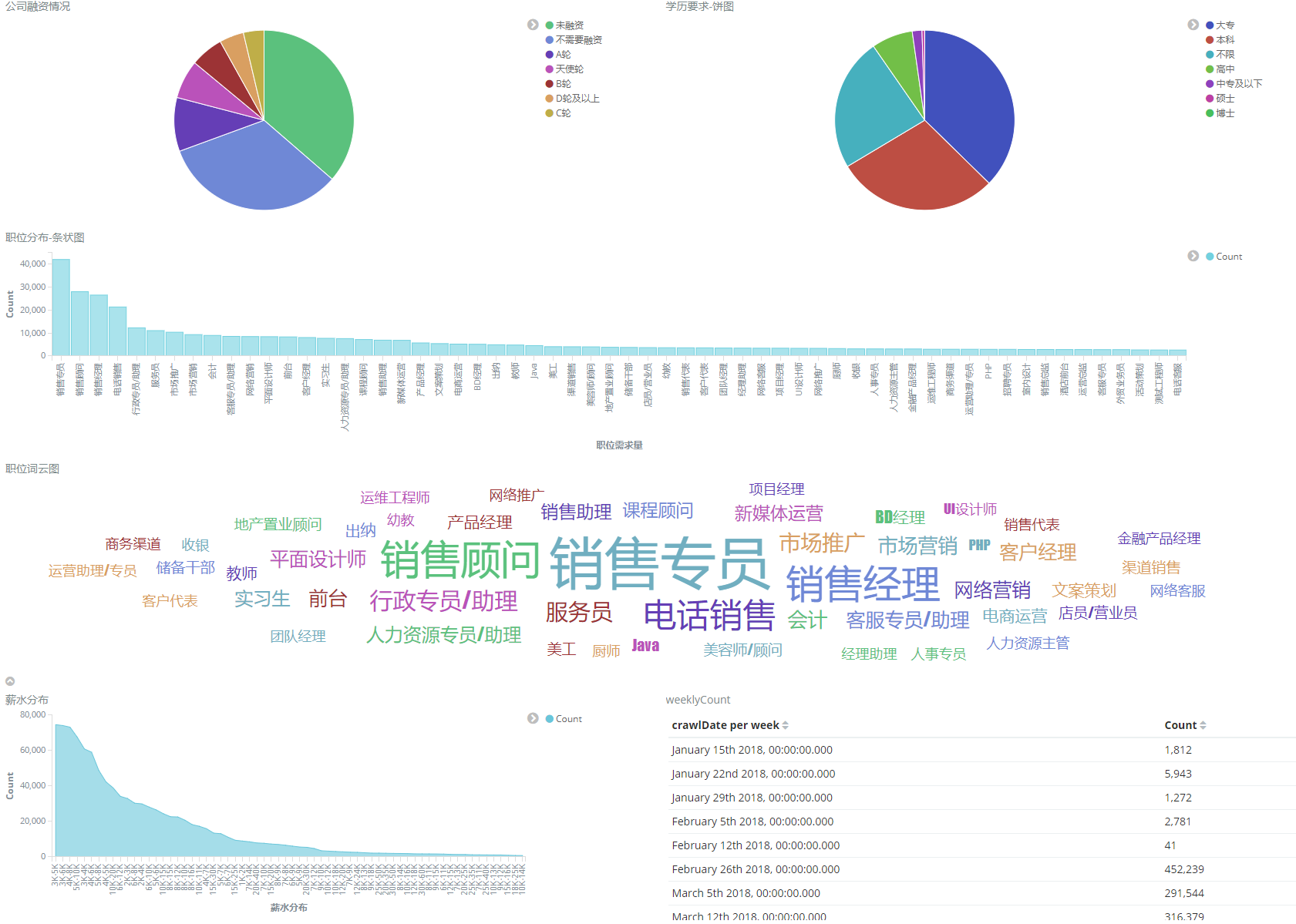
各环节均支持自定义 示例抓取CSDN某用户的博客内容设置爬虫的基本配置,如User-Agent、起始地址、目标页面的url正则表达式、线程数和超时时间等 new VWCrawler.Builder() // 配置参数 .setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36") // 设置请求头 .setUrl("https://blog.csdn.net/qqhjqs") // 设置爬虫起始地址 .setThreadCount(10) // 设置几个线程抓取数据 .setTimeOut(5000) // 设置超时时间 // 抽象正则 .setTargetUrlRex("https://blog.csdn.net/qqhjqs/article/details/[0-9]+") // 设置目标页面url的正则表达式 // 解析页面 .setPageParser(new CrawlerService<Blog>() { /** * 有的url可能在某个场景下不需要可在此处理 * 默认返回false,可以不做处理 * @param url 即将要抓取的url * @return */ @Override public boolean isExist(String url) { if ("https://blog.csdn.net/qqhjqs/article/details/79101846".equals(url)) { return true; } return false; } /** * 有的页面有WAF,可以再真正解析前,做个判断,遇到特殊标志的直接可以跳过 * 默认返回true,可以不做处理 * @param document 即将要解析的document * @return */ @Override public boolean isContinue(Document document) { if ("最近和未来要做的事 - CSDN博客".equals(document.title())) { System.out.println("模拟遇到WAF此页面不做解析"); return false; } return true; } /** * 目标页面的doc对象,还有通过注解处理后的对象 * @param doc 文档内容 * @param pageObj 封装的对象 */ @Override public void parsePage(Document doc, Blog pageObj) { // 可进行二次处理 pageObj.setReadNum(pageObj.getReadNum().replace("阅读数:", "")); } // 保存数据 /** * 可以做保存对象的处理 * @param pageObj 页面对象 */ @Override public void save(Blog pageObj) { System.out.println("save blog summery: " + pageObj.toString()); } }) // 自定义解析service .build().start(); // 启动配置页面数据对象的注解 @CssSelector(selector = "#mainBox > main > div.blog-content-box > div.article-title-box > h1", resultType = SelectType.TEXT)private String title;@CssSelector(selector = "#mainBox > main > div.blog-content-box > div.article-info-box > div > span.time", dateFormat = "yyyy年MM月dd日 HH:mm:ss")private Date lastUpdateDate;@CssSelector(selector = "#mainBox > main > div.blog-content-box > div.article-info-box > div > div > span", resultType = SelectType.TEXT)private String readNum;这里使用比较流行的注解方式,通过cssselector来获取节点数据可通过resultType来指定填充的是text还是html。 随便配置一下,就能抓取一个页面的数据 new VWCrawler.Builder().setUrl("https://www.qiushibaike.com/").setPageParser(new CrawlerService() { @Override public void parsePage(Document doc, Object pageObj) { System.out.println(doc.toString()); } @Override public void save(Object pageObj) { }}).build().start();更多更多的示例可移步more 抓取了足够多的数据,我们可以拿数据做很多事,比如统计各大人才网的职位分布图 源码 最后轮子造多了就想着造一个模具,代码写多了就想写个框架,一样的道理。帮助他人,顺便提升自己。框架还有很多需要完善的地方,希望使用者多多提issue,也希望大家提PR~~~ 欢迎大家访问  |












请发表评论