
-
 客服电话
客服电话
-
 APP下载
APP下载
迪恩网络APP
随时随地掌握行业动态

-
 官方微信
官方微信
扫描二维码
关注迪恩网络微信公众号
客服电话
APP下载
迪恩网络APP
随时随地掌握行业动态
官方微信
扫描二维码
关注迪恩网络微信公众号
开源软件名称:neocrawler开源软件地址:https://gitee.com/dreamidea/neocrawler开源软件介绍:一、概述NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。 【主要特点】
可配置项: 1). 用正则表达式来描述,类似的网页归为一类,使用相同的规则。一个爬虫系统(下面几条指的都是某类网址可配置项); 2). 起始地址、抓取方式、存储位置、页面处理方式等; 3). 需要收集的链接规则,用CSS选择符限定爬虫只收集出现在页面中某个位置的链接; 3). 页面摘取规则,可以用CSS选择符、正则表达式来定位每个字段内容要抽取的位置; 4). 预定义要在页面打开后注入执行的js语句; 5). 网页预设的cookie; 6). 评判该类网页返回是否正常的规则,通常是指定一些网页返回正常后页面必然存在的关键词让爬虫检测; 7). 评判数据摘取是否完整的规则,摘取字段中选取几个非常必要的字段作为摘取是否完整的评判标准; 8). 该类网页的调度权重(优先级)、周期(多久后重新抓取更新)。
【架构】提示:建议刚接触本系统的用户跳过架构介绍环节直接进入第二部分,先将系统运行起来,有一个感性认识后再来查阅架构的环节,如果您需要做深入的二次开发,请仔细阅读本环节资料 整体架构
图中黄色部分为爬虫系统的各个子系统。
二、运行步骤##【运行环境准备】
create 'crawled',{NAME => 'basic', VERSIONS => 3},{NAME=>"data",VERSIONS=>3},{NAME => 'extra', VERSIONS => 3}create 'crawled_bin',{NAME => 'basic', VERSIONS => 3},{NAME=>"binary",VERSIONS=>3}推荐使用hbase rest方式, 当你启动hbase后, 在hbase目录的bin子目录下执行以下命令可以启动hbase rest: ./hbase-daemon.sh start rest默认端口为8080, 下面配置中会用到. ##【实例配置】
{ /*注意:此处用于解释各项配置,真正的setting.json中不能包含注释*/ "driller_info_redis_db":["127.0.0.1",6379,0],/*网址规则配置信息存储位置,最后一个数字表示redis的第几个数据库*/ "url_info_redis_db":["127.0.0.1",6379,1],/*网址信息存储位置*/ "url_report_redis_db":["127.0.0.1",6380,2],/*抓取错误信息存储位置*/ "proxy_info_redis_db":["127.0.0.1",6379,3],/*http代理网址存储位置*/ "use_proxy":false,/*是否使用代理服务*/ "proxy_router":"127.0.0.1:2013",/*使用代理服务的情况下,代理服务的路由中心地址*/ "download_timeout":60,/*下载超时时间,秒,不等同于相应超时*/ "save_content_to_hbase":false,/*是否将抓取信息存储到hbase,目前只在0.94下测试过*/ "crawled_hbase_conf":["localhost",8080],/*hbase rest的配置,你可以使用tcp方式连接,配置为{"zookeeperHosts": ["localhost:2181"],"zookeeperRoot": "/hbase"},此模式下有OOM Bug,不建议使用*/ "crawled_hbase_table":"crawled",/*抓取的数据保存在hbase的表*/ "crawled_hbase_bin_table":"crawled_bin",/*抓取的二进制数据保存在hbase的表*/ "statistic_mysql_db":["127.0.0.1",3306,"crawling","crawler","123"],/*用来存储抓取日志分析结果,需要结合flume来实现,一般不使用此项*/ "check_driller_rules_interval":120,/*多久检测一次网址规则的变化以便热刷新到运行中的爬虫*/ "spider_concurrency":5,/*爬虫的抓取页面并发请求数*/ "spider_request_delay":0,/*两个并发请求之间的间隔时间,秒*/ "schedule_interval":60,/*调度器两次调度的间隔时间*/ "schedule_quantity_limitation":200,/*调度器给爬虫的最大网址待抓取数量*/ "download_retry":3,/*错误重试次数*/ "log_level":"DEBUG",/*日志级别*/ "use_ssdb":false,/*是否使用ssdb*/ "to_much_fail_exit":false,/*错误太多的时候是否自动终止爬虫*/ "keep_link_relation":false/*链接库里是否存储链接间关系*/}##【运行】
以下是具体的启动命令
可以在instance/example/logs 下查看输出日志debug-result.json 在正式运行的环境下建议使用nodejs 的 pm2或者python的supervisor来托管进程. ##【抓取规则配置】打开web界面,例如:http://localhost:8888/ , 进入“Drilling Rules”,添加规则。这是一个json编辑器,可以在代码模式/可视化模式之间切换。下面给出配置项的说明.具体的应用配置可以参考下一章节的示例. { /*注意:此处用于解释各项配置,真正的配置代码中不能包含注释*/ "domain": "",/*顶级域名,例如163.com(不带主机名,www.163.com是错误的)*/ "url_pattern": "",/*网址规则,正则表达式,例如:^http://domain/\d+\.html,限定范围越精确越好*/ "alias": "",/*给该规则取的别名*/ "id_parameter": [],/*该网址可以带的有效参数,如果数组第一个值为#,表示过滤一切参数*/ "encoding": "auto",/*页面编码,auto表示自动检测,可以填写具体值:gbk,utf-8*/ "type": "node",/*页面类型,分支branch或者节点node*/ "save_page": true,/*是否保存html源代码*/ "format": "html",/*页面形式,html/json/binary*/ "jshandle": false,/*是否需要处理js,决定了爬虫是否用phantomjs加载页面*/ "extract_rule": {/*摘取规则,后面单独详述*/ "category": "crawled", "rule": {/*如果不摘取数据,rule应该为空*/ "title": {/*一个摘取单元,后面单独详述*/ "base": "content", "mode": "css", "expression": "title", "pick": "text", "index": 1 } } }, "cookie": [],/*cookie值,有多个object组成,每个object是一个cookie值*/ "inject_jquery": false,/*在使用phantomjs的情况下是否注入jquery*/ "load_img": false,/*在使用phantomjs的情况下是否载入图片*/ "drill_rules": ["a"],/*页面中感兴趣的链接,填写css选择符选择a元素,可以为多个,此处表示所有链接*/ "drill_relation": {/*一个摘取单元,从页面中摘取一个值来填充上下文关系对此页的描述*/ "base": "content", "mode": "css", "expression": "title", "pick": "text", "index": 1 }, "validation_keywords": [],/*验证页面下载是否有效的关键词,可以为多个,为空表示不验证*/ "script": [],/*在页面中执行的脚本,可以为多个,依次对应每个层级下的执行。以js_result=..形式*/ "navigate_rule": [],/*自动导航,css选择符,可以为多个,依次对应每个层级,phantomjs将点击匹配的元素进行导航*/ "stoppage": -1,/*导航几个层级后停止*/ "priority": 1,/*调度优先级,数字越小越优先*/ "weight": 10,/*调度权重,数字越大越有限*/ "schedule_interval": 86400,/*重新调度的周期,单位秒*/ "active": true,/*是否激活该规则*/ "seed": [],/*种子地址,重新调度时从这些网址开始*/ "schedule_rule": "FIFO"/*调度方式,FIFO或者LIFO*/}摘取单元{"base": "content",/*基于什么摘取,网页DOM:content或者给予url*/ "mode": "css",/*摘取模式,css或者regex表示css选择符或者正则表达式,value表示给固定值*/ "expression": "title",/*表达式,与mode相对应css选择符表达式或者正则表达式,或者一个固定的值*/ "pick": "text",/*css模式下摘取一个元素的属性或者值,text、html表示文本值或者标签代码,@href表示href属性值,其他属性依次类推在前面加@符号*/ "index": 1/*当有多个元素时,选取第几个元素,-1表示选择多个,将返回数组值*/}摘取规则/*摘取规则由多个摘取单元构成,它们之间的基本结构如下*/"extract_rule": { "category": "crawled",/*该节点存储到hbase的表名称*/ "rule": {/*具体规则*/ "title": {/*一个摘取单元,规则参考上面的说明*/ "base": "content", "mode": "css", "expression": "title", "pick": "text", "index": 1, "subset":{/*子集*/ "category":"comment",/*属于comment(存储到comment)*/ "relate":"#title#",/*与上级关联*/ "mapping":false,/*子集类型,mapping为true将分到另外的表中单独存储*/ "rule":{ "profile": {"base":"content","mode":"css","expression":".classname","pick":"@href","index":1},/*摘取单元*/ "message": {"base":"content","mode":"css","expression":".classname","pick":"@alt","index":1} }, "require":["profile"]/*必须字段*/ } } } "require":["title"]/*必须字段,如果里面的值为数组,表示这个数组内的值有任意一个就满足要求,例如[[a,b],c]*/ }三、简单示例此步骤假设你已经将web配置后台运行起来了,如何运行web配置请按照上一章节的说明 下面列出一个抓取微信号的配置例子.假设我们的意图是抓取http://www.sovxin.com 上的所有微信号. 第一步是观察网站的结构,大概可以分为4个层次:首页,分类频道页,列表页,详情页.我们根据这个页面层次来进行抓取规则的配置,其中,只有详情页是需要配置字段摘取信息的,其他3种页面都是用来逐步发现详情页的.我们将这个顺序倒过来,从详情页开始配置,最后再看首页.##规则列表截图(你的界面肯定还没有这些规则列表,点击Add添加规则,参考我下面列出的配置) 详情页(摘取实际内容的)
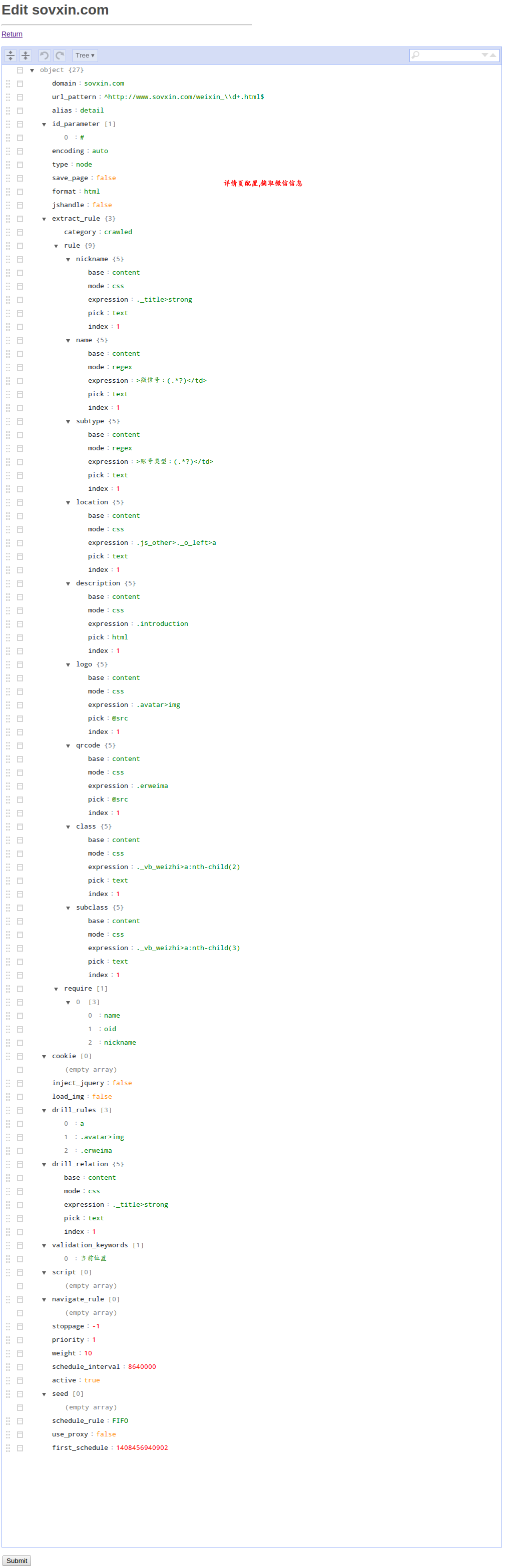
你应当对照上一章节讲到的每个配置项的说明来理解这个示例 可以将编辑器切换到代码模式,将下面的json粘贴到里面. { "domain": "sovxin.com", "url_pattern": "^http://www.sovxin.com/weixin_\\d+.html$", "alias": "detail", "id_parameter": [ "#" ], "encoding": "auto", "type": "node", "save_page": false, "format": "html", "jshandle": false, "extract_rule": { "category": "crawled", "rule": { "nickname": { "base": "content", "mode": "css", "expression": "._title>strong", "pick": "text", "index": 1 }, "name": { "base": "content", "mode": "regex", "expression": ">微信号:(.*?)</td>", "pick": "text", "index": 1 }, "subtype": { "base": "content", "mode": "regex", "expression": ">账号类型:(.*?)</td>", "pick": "text", "index": 1 }, "location": { "base": "content", "mode": "css", "expression": ".js_other>._o_left>a", "pick": "text", "index": 1 }, "description": { "base": "content", "mode": "css", "expression": ".introduction", "pick": "html", "index": 1 }, "logo": { "base": "content", "mode": "css", "expression": ".avatar>img", "pick": "@src", "index": 1 }, "qrcode": { "base": "content", "mode": "css", "expression": ".erweima", "pick": "@src", "index": 1 }, "class": { "base": "content", "mode": "css", "expression": "._vb_weizhi>a:nth-child(2)", "pick": "text", "index": 1 }, "subclass": { "base": "content", "mode": "css", "expression": "._vb_weizhi>a:nth-child(3)", "pick": "text", "index": 1 } }, "require": [ [ "name", "oid", "nickname" ] ] }, "cookie": [], "inject_jquery": false, "load_img": false, "drill_rules": [ "a", ".avatar>img", ".erweima" ], "drill_relation": { "base": "content", "mode": "css", "expression": "._title>strong", "pick": "text", "index": 1 }, "validation_keywords": [ "当前位置" ], "script": [], "navigate_rule": [], "stoppage": -1, "priority": 1, "weight": 10, "schedule_interval": 8640000, "active": true, "seed": [], "schedule_rule": "FIFO", "use_proxy": false, "first_schedule": 1408456940902}列表页(通过它摘取到上面配置的详情页链接以及本身的分页链接)
{ "domain": "sovxin.com", "url_pattern": "^http://www.sovxin.com/t_.*?.html$", "alias": "list", "id_parameter": [ "#" ], "encoding": "auto", "type": "branch", "save_page": false, "format": "html", "jshandle" |













请发表评论