








R语言1-面板数据分析全过程 附代码
# 用途
面板数据常见于计量经济学领域,本质上是一种线性回归方法。截面数据和时间序列数据的组合可以更多的反应数据情况,同时也需要克服二者都存在的问题。
## 数据初步处理
在Excel中将原数据进行初步处理和排列并另存为csv格式,建议将文件存放于便于提取的路径下。
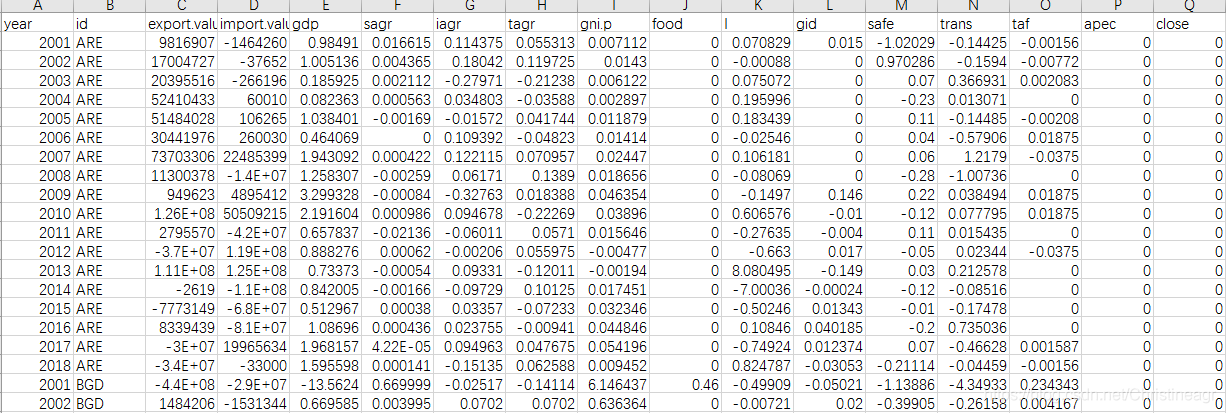
因变量为export.value,自变量分别为gdp、sagr、iagr、tagr、gni.p、food…其中apec和close是哑变量。截面为27个国家,时间跨度为2001-2018年。
## 数据清洗
在现实的经济数据中,数据不可避免的会存在缺失等问题。因此需要对数据进行清洗,并对缺失数据集进行插补。插补方法较多,R为面板数据提供了专门的程辑包:pan包。
首先进行缺失数据的可视化,然后针对缺失数据集进行插补。注意因变量应该是完整的,pan包主要是处理自变量的缺失。
[ 详细的插补步骤和方法请参考这篇博文
](https://blog.csdn.net/sinat_26917383/article/details/51265213?depth_1-utm_source=distribute.pc_relevant.none-
task-blog-BlogCommendFromBaidu-2&utm_source=distribute.pc_relevant.none-task-
blog-BlogCommendFromBaidu-2)
## 面板数据的单位根检验
```code
// 读取数据
lndataI<-read.csv("E://lndataI.csv",header = TRUE);
lnDATAI<-as.matrix(lndataI[,3:15])
//加载程辑包
library(plm)
//matrix形式简化检验步骤
purtest(lnDATAI,test = c("levinlin"),exo = c("trend"),lags = c("AIC"),pmax = 10)
//可选参数
test = c("levinlin", "ips", "madwu", "Pm", "invnormal", "logit", "hadri"),
exo = c("none", "intercept", "trend"),
lags = c("SIC", "AIC", "Hall")
```
注意:五种检验方式中,只有Hadri函数的原假设为平稳,其他均为不平稳。
若0阶不平稳,则对原数据进行差分再进行单位根检验,直至平稳。
## 协整检验
1.pco包提供 _pedroni99m_
方法。每个变量分割成矩阵再结合成(多维)数组,第一个矩阵必须是自变量,其余为因变量。每个矩阵第一维(行)是时间,第二维(列)是个体(截面),第三维是变量值。
_该函数最多检验7维数组_ ,即最多检验7个变量。
当standardized value服从标准正态分布(0,1)时,服从H0假设,即数组不协整。
引入ks检验标准正态分布
```code
// pedroni99m协整检验
pedroni99m(array(t1,dim = c(19,27,6)),type.stat = 2)
//标准正态分布检验
ks.test(standardized value,"pnorm",mean=0,sd=1)
```
2.urca包提供ca.jo检验
最多检验11个变量,包容哑变量。但变量个数增多后会导致不显示边界值,很不方便。可以通过修改源代码,增加检验变量个数,同时显示所有的critical
values。
亲测可行
代码太长就不贴了。
## 面板回归详细代码
```code
// 读入标准面板格式数据
panel<-pdata.frame(data,index = c("year","id"))
//构建固定模型-双效应/时间效应/个体效应
fix<-plm(export.value~gdp+sagr+iagr+tagr+gni.p+I+food+gid+safe+trans+taf+culture+apec+close,data = panel,model = "within")
fix_two<-plm(export.value~gdp+sagr+iagr+tagr+gni.p+I+food+gid+safe+trans+taf+culture+apec+close,data = panel,model = "within",effect = "twoways")
fix_time<-plm(export.value~gdp+sagr+iagr+tagr+gni.p+I+food+gid+safe+trans+taf+culture+apec+close,data = panel,model = "within",effect = "time")
fix_individual<-plm(export.value~gdp+sagr+iagr+tagr+gni.p+I+food+gid+safe+trans+taf+culture+apec+close,data = panel,model = "within",effect = "individual")
//构建随机模型-双效应/时间效应/个体效应
ran<-plm(export.value~gdp+sagr+iagr+tagr+gni.p+I+food+gid+safe+trans+taf+culture+apec+close,data = panel,model = "random")
ran_two<-plm(export.value~gdp+sagr+iagr+tagr+gni.p+I+food+gid+safe+trans+taf+culture+apec+close,data = panel,model = "random",effect = "twoways")
ran_time<-plm(export.value~gdp+sagr+iagr+tagr+gni.p+I+food+gid+safe+trans+taf+culture+apec+close,data = panel,model = "random",effect = "time")
ran_individual<-plm(export.value~gdp+sagr+iagr+tagr+gni.p+I+food+gid+safe+trans+taf+culture+apec+close,data = panel,model = "random",effect = "individual")
//混合模型
pool<-plm(export.value~gdp+sagr+iagr+tagr+gni.p+I+food+gid+safe+trans+taf+culture+apec+close,data = panel,model = "pooling")
//F检验-个体or时间
pooltest(fix_time,fix_individual)
//F检验-混合or固定
pooltest(fix,pool)
//豪斯曼检验-随机or固定
phtest(fix,ran)
//==共线性检验==方差膨胀因子
library(car)
vif(ran)
vif(pool)
vif(fix)
//==共线性检验==kappa
kappa(panel[,3:18])
```
## 结果分析
略






